Otrdiena, 15. jūlijs


|
|
Latvijas Zinātņu akadēmijaLatvian Academy of Sciences |
Zinātnes VēstnesisZinātnes Vēstnesis - 201914.janvāris, 1 (564) 28.janvāris, 2 (565) 11.februāris, 3 (566) 25.februāris, 4 (567) 11.marts, 5 (568) 25.marts, 6 (568) 8.aprīlis, 7 (570) 22.aprīlis, 8 (571) 6.maijs, 9 (572) 20.maijs, 10 (573) 3.jūnijs, 11 (574) 17.jūnijs, 12 (575) 1.jūlijs, 13 (576) 16.septembris, 14 (577) 30.septembris, 15 (578) 14.oktobris, 16 (579) 28.oktobris, 17 (580) 11.novembris, 18 (581) 25.novembris, 19 (582) 9.decembris, 20 (583) 23.decembris, 21 (584)Jaunākais ZV
|
Identitātes digitizācijas procesi, jeb kā domāt par cilvēku internetā? Literatūrzinātnieces meklējumi IT jomā

Zinātnes Vēstnesis
- 2019.g. 25.marts
23-03-2019
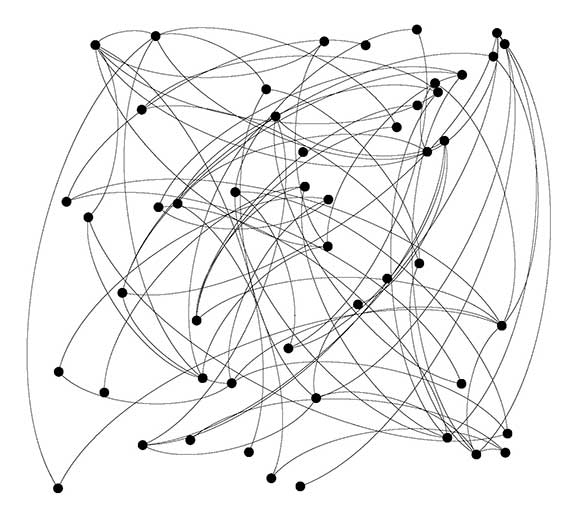
Plašākajā mērogā pētījums atklās jēdzieniskās, tematiskās un žanriskās likumsakarības starp liela apjoma datiem (tekstiem), palīdzēs risināt autorības un palģiātisma jautājumus, ietekmēs literāro kontekstu uztveres veidus. Ja pašlaik ir pieņemts uzskatīt, ka kontekstu veido teksta tapšanas laiks, vieta, vēsturiskie faktori, tad Marijas pētījuma rezultātā būs iespējams nonākt līdz teksta veidojošo kontekstu iemesliem (piemēram, kādos apstākļos ir dzīvojis konkrēts autors un kā šie apstākļi ietekmēja žanra veidošanas procesus un cits). Lai padarītu rezultātus uzskatamākus un vienlaikus rast inovatīvu risinājumu datu atspoguļojumā, pētījuma ietvaros tiek izstrādātas teksta molekulas, kuras ir tekstu digitālās analīzes reprezentācijas 3D un 2D formā. Molekulu būtība ir aprakstītu žanrisko, tematisko un jēdzienisko likumsakarību atspoguļošana un turpmākās salīdzinošās analīzes vienkāršošana (skat. attēlu 1 3D modelis-molekula).
Molekulu pamatā ir tekstu statistiskā analīze, vārdu garuma un atšķirības starp burtiem noteikšana un salikšana digitālajās kopās (klāsteros). Grafiski šie klāsteri parādās punktu (nodu) veidā un apzīmē noteiktu tekstu skaitu, kas nevar būt mazāks par 20 vienībām. Šāda tekstu analīze sniedz iespēju paskatīties uz literāro un virtuālo procesu no tā dēvētās distancētas perspektīvas jeb pielietot distancētās lasīšanas prinicipu, kas šajā gadījumā ir apzināti pretstatīts ierastajam tuvlasījuma principam, kurā ir svarīgas, piemēram, māksliniecisko izteiksmes līdzekļu lietošanas motivācija, izkārtojums tekstā. Pētījuma gaita skar ne tikai literārus tekstus, bet analizē arī internetā esošus lielus datus - dažāda tipa blogu tekstus, sociālo tīklu ierakstus un komentārus. Tādējādi pētījumam tiek piešķirta arī publiskā un praktiskā nozīme. Datus papildina arī ‘reālās prakses' piemēri, kuri tiek vākti ritējošā lauka pētījuma rezultātā. Tā veikšanai un datu aprobācijai un popularizācijai Marija ir izveidojusi pētnieku grupu, kura pašlaik darbojās LU Humanitāro zinātņu fakultātē. Pētījums ir viens no pirmajiem soļiem Latvijā digitālo humanitāro zinātņu potenciāla apzināšanā. |
 Filoloģijas doktores, LU Humanitāro zinātņu fakultātes pētnieces Marijas Semjonovas jaunākais pētījums sākās kā zinātnisks izaicinājums salīdzināmās literatūrzinātnes jomā, jo tā pirmā ideja bija - apvienot digitālo (tātad, matemātikā balstīto) analīzi ar klasisko literatūras analīzi (jeb tekstu lasīšanu). Līdz šādai idejai pētniece ir nonākusi, domājot par mūsdienu literatūras procesa daudzlīmeņaino un bieži pretrunīgu dabu, kuru vairs nav iespējams lūkot vienā vai citā domāšanas paradigmā. Ņemot vērā pieņēmumu, ka literārais process ir daudzpusīgs, kuram ir raksturīga tematiskā un žanriskā uzslāņošanās, pētījums sākās ar pieņēmumu, ka pastāv iespēja skatīt savstarpējas likumsakarības starp tekstiem no tāllasīšanas perspektīvas. Lai gan jēdziens pats par sevi nav jauns un pirmās publikācijas par šo lasīšanas paņēmienu ir iznākušās vēl 2013. gadā, Marijas pieņēmums ietvēra ideju analizēt literārus un internetā atrodamus tekstus (piem., blogu ierakstus, tvītus, Facebook ierakstus un komentārus), izmantojot digitālus rīkus, kuriem pamatā ir statistiskā analīze. Realitātē tas nozīmē tekstos atrodamo vārdu līdzību un atšķirību ‘saskaitīšanu' un savstarpēju salīdzināšanu. Vienkāršāk, pētnieces metode paredz semantisko vienību - vārdu - digitālās analīzes veikšanu. Tā rezultātā tiek digitāli konstruēti tekstos biežāk lietotu vārdu saraksti, kas ir raksturīgi visiem analizējamiem tekstiem vienlaikus. Metode paredz arī, ka analīze tiek veikta nevis diviem vai trim literāriem vai interneta vidē atrodamiem tekstiem, bet gan lielāka apjoma tekstu kopai (viens solis vienādojams ar vismaz 20 pilnā apjoma analizējamiem tekstiem).
Filoloģijas doktores, LU Humanitāro zinātņu fakultātes pētnieces Marijas Semjonovas jaunākais pētījums sākās kā zinātnisks izaicinājums salīdzināmās literatūrzinātnes jomā, jo tā pirmā ideja bija - apvienot digitālo (tātad, matemātikā balstīto) analīzi ar klasisko literatūras analīzi (jeb tekstu lasīšanu). Līdz šādai idejai pētniece ir nonākusi, domājot par mūsdienu literatūras procesa daudzlīmeņaino un bieži pretrunīgu dabu, kuru vairs nav iespējams lūkot vienā vai citā domāšanas paradigmā. Ņemot vērā pieņēmumu, ka literārais process ir daudzpusīgs, kuram ir raksturīga tematiskā un žanriskā uzslāņošanās, pētījums sākās ar pieņēmumu, ka pastāv iespēja skatīt savstarpējas likumsakarības starp tekstiem no tāllasīšanas perspektīvas. Lai gan jēdziens pats par sevi nav jauns un pirmās publikācijas par šo lasīšanas paņēmienu ir iznākušās vēl 2013. gadā, Marijas pieņēmums ietvēra ideju analizēt literārus un internetā atrodamus tekstus (piem., blogu ierakstus, tvītus, Facebook ierakstus un komentārus), izmantojot digitālus rīkus, kuriem pamatā ir statistiskā analīze. Realitātē tas nozīmē tekstos atrodamo vārdu līdzību un atšķirību ‘saskaitīšanu' un savstarpēju salīdzināšanu. Vienkāršāk, pētnieces metode paredz semantisko vienību - vārdu - digitālās analīzes veikšanu. Tā rezultātā tiek digitāli konstruēti tekstos biežāk lietotu vārdu saraksti, kas ir raksturīgi visiem analizējamiem tekstiem vienlaikus. Metode paredz arī, ka analīze tiek veikta nevis diviem vai trim literāriem vai interneta vidē atrodamiem tekstiem, bet gan lielāka apjoma tekstu kopai (viens solis vienādojams ar vismaz 20 pilnā apjoma analizējamiem tekstiem).